We’ve had questions regarding the output format for track 1, which has caused some confusion amongst our participants. We want to clarify this in the following post.
Each point in the expected output format, which we detail also in our template here, looks like this:
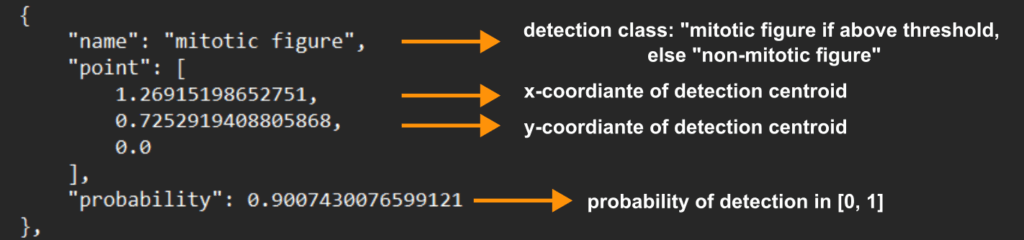
A cause of confusion seems to be that here, the detections are either carry the “name” of “mitotic figure” or of “non-mitotic figure”.
The MIDOG challenge is a one-class object detection problem, so in terms of detection, we are only interested in mitotic figures, not in non-mitotic figures, which are also in parts of our datasets given as “hard examples”. It is also worth knowing that the “non-mitotic figure” annotations of our datasets are not complete, i.e., they do not consider every possible non-mitotic figure, and are thus not even suitable for training a two-class object detector.
Now why do we need this field then, if we are only looking for “mitotic figure”s? We use this field to decide between above threshold and below threshold detections. In all major object detection frameworks, each detection also has a confidence value. The final step in optimization is always to determine a threshold for the detection. Effectively, this threshold trades false positives for false negatives, and thus sets the operating point of the model.
Some metrics, like the average precision metric, require the complete (i.e. unthresholded) set of predictions, however.
So, in a nutshell:
- Provide all your detections in the list
- Indicate which ones are true detections (i.e., above threshold) with the field “name”, whereas above threshold detections need to carry the name “mitotic figure”, and below threshold detections carry the name “non-mitotic figure”.